Transformers and Self-Attention#
Note
For the explanation of decoder-based architectures such as those used by GPT, please see the repo pantelis/femtotransformers and the embedded comments therein. A future version of this section will incorporate the commented source code from that repo as well as this popular repo that implements various other transformer architectures.
![]()
This is the original encoder-decoder architecture
As compared to the RNNs we have seen earlier, in the transformer architecture we
Eliminate all recurrent connections present in earlier RNN architectures, therefore allowing the model to be trained as well as produce inference results much faster.
Continue to use attention mechanisms to allow the model to focus on the most relevant parts of the input sequence. The attention mechanisms will be present in the encoder as well as the decoder part of the architecture if the transformer we are using has both of these parts obviously.
This means that the encoder output for each input token will be a weighted sum of all other tokens, where the weights are computed by an attention mechanism called self-attention. The ‘self’ refers to the current token’s generalized dot product with each and every other token of the input sequence itself.
Simple self-attention mechanism#
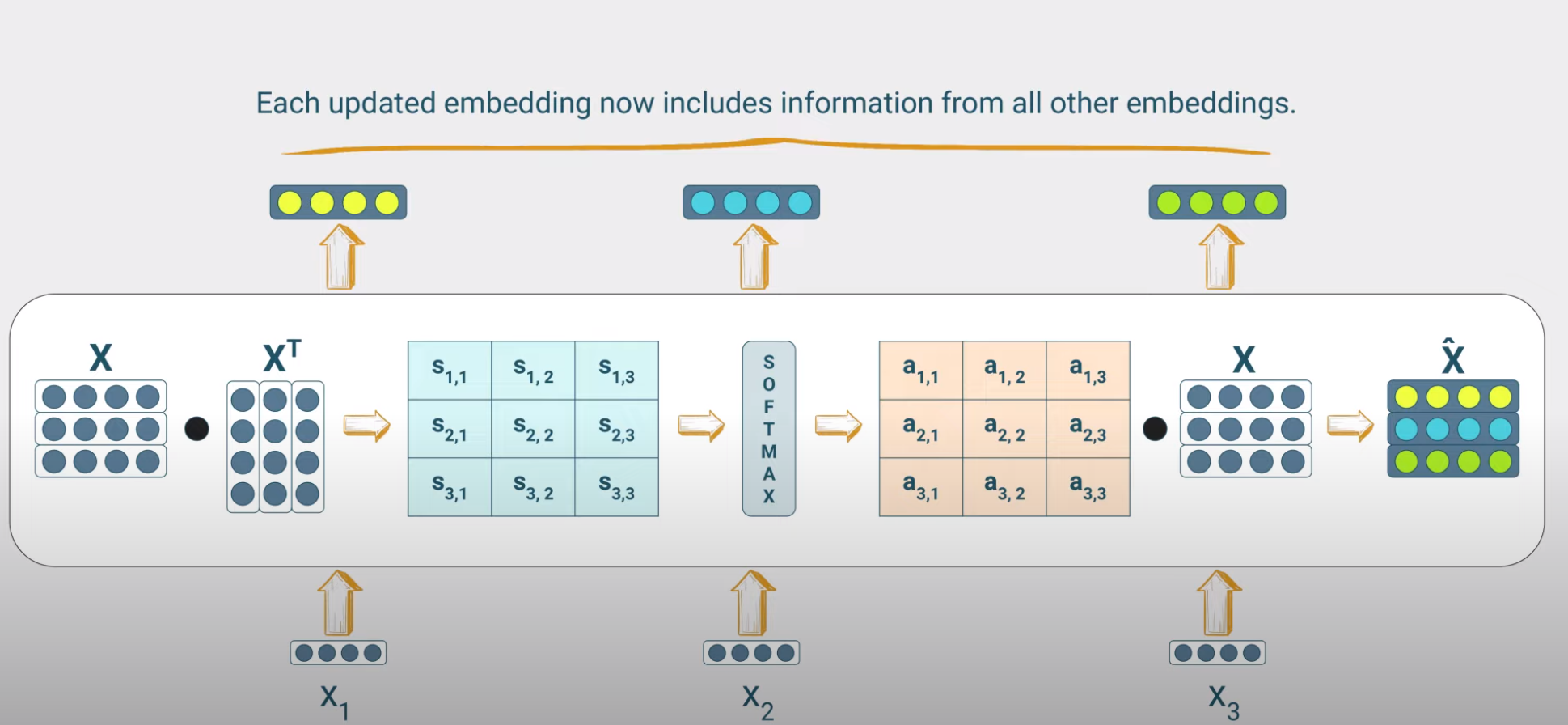
In the figure above, a token is [dx1] vector with \(d=4\) and we have \(T=3\) tokens as the input sequence length (typically called block size). Note on shown dimensions: We are in the process of modifying the figures to be inline with the nanoGPT (included in femtotransdformers) - the batch dimension is not shown here.
The self-attention mechanism is a mechanism that allows the model to focus on the most relevant parts of the input sequence. Given the \(i-th\) input token having embedding \(x_i\), we perform the following calculations:
Attention scores of the input token: These are computed as dot products of the embedding of the input token and each of the embeddings of the tokens of the input sentence (including the input token itself). For example if the input sequence consists of 3 tokens, we will compute 3 attention scores for each token to obtain a 3x3 tensor.
Attention weights: The attention scores are then passed through a softmax function to obtain the corresponding attention weights. Recall that the softmax function is a vector input - vector output function that maps the input vector to a vector of values between 0 and 1, where the sum of all values is 1. So we expect to get 3 attention weights.
Weighted embedding of the input token : We then use the attention weights to create a weighted sum of the token embeddings of the input sequence to obtain the new input token embedding i.e. the embedding that now includes information from all other embeddings of the input sequence.
where \(\alpha_{ij}\) is the attention weight of the \(j-th\) token of the input sequence for the \(i-th\) token of the input sequence of length T.
Self-attention layers can be stacked on top of each other to create a multi-layer self-attention mechanism.
Resources#
An interesting video for the many attention mechanisms that are the roots of self-attention found in transformers.
Perhaps one of the best overviews of Transformers around with an implementation in TF.